Identifying who exported that leaked CSV

Today’s topic is more like an academic exercise than a production use case, but there are a lot of learnings along the way and I think it’s worth the effort.
The other day I saw a tweet by Igor Cotruta that talked about «text fingerprinting». The idea is embedding the user id in invisible characters so that if the exported data get’s eventually leaked it can be traced back to whoever exported it. Looks like stuff from a spy movie, so I was quickly on-board in the attempt to reproduce that with Power BI with a Calc Group.
In Power BI we have a function called USERPRINCIPALNAME() that returns sort of the current user id and can be used for some customizations at user level, such as default filter values for slicers. So the idea was to convert that to binary, then convert the ones and zeros to two different kinds of zero-width characters (turns out there’s quite a few of them) and sneak it in the data with the user unaware of it. I tried to follow the same characters as the original article by Tom Ross
- Zero width space:
- This will be my 1.
- Character.FromNumber(8203)
- UNICHAR(8203)
- When developing I use «x»
- Zero width non-joiner:
- This will be my 0.
- Character.FromNumber(8204)
- UNICHAR(8204)
- When developing I use «y»
- Zero width joiner:
- This will separate my invisible binary-encoded letters.
- Character.FromNumber(8205)
- UNICHAR(8205)
- When developing I use «z»
- Zero width non-breaking space:
- This will separate my hidden string from the rest of what may come from the measure in the report.
- Character.FromNumber(65279)
- UNICHAR(65279)
- When developing I use «k»
After fighting with it through DAX and Power Query, I came up with a blended approach, in which I create a Conversion Table, in which all letters and symbols that may appear in the id are given an invisible binary-based string code. Here important, when we say binary we mean zeros and ones, not the binary often viewed in Power Query that refers to File contents (that caused me much grieve searching in google).
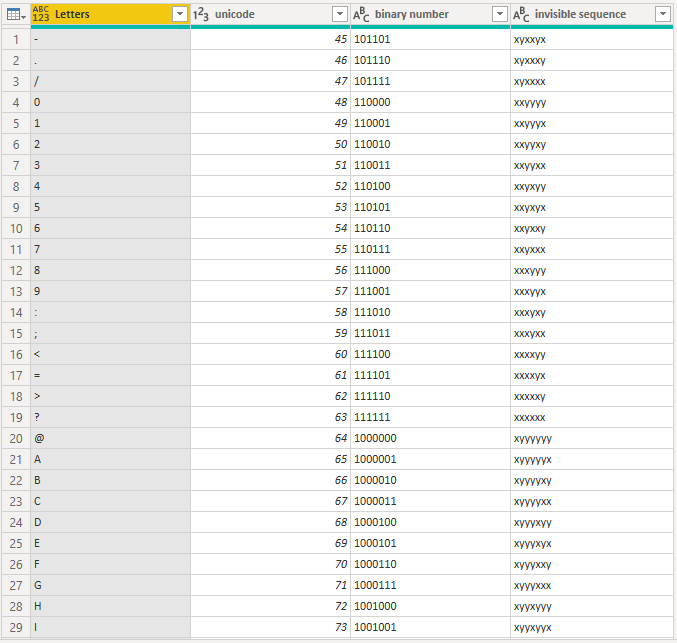
First things first, I needed a conversion table from Letter to binary invisible letters, and I included upper case lower case, everything that a saw in my own USERPRINCIPALNAME(). After searching around the internet for a while I came up with a nice table (by the way, if you didn’t know, now you know: there’s a website called Power Query Formatter that will make your code look good and give you the html code to include power query code in your blog)
let Source = { "-" .. "z" }, #"Converted to Table" = Table.FromList ( Source, Splitter.SplitByNothing(), null, null, ExtraValues.Error ), #"Renamed Columns" = Table.RenameColumns ( #"Converted to Table", { { "Column1", "Letters" } } ), #"Added Custom" = Table.AddColumn ( #"Renamed Columns", "unicode", each Character.ToNumber ( [Letters] ) ), #"Changed Type" = Table.TransformColumnTypes ( #"Added Custom", { { "unicode", Int64.Type } } ), #"Added Custom1" = Table.AddColumn ( #"Changed Type", "binary number", each #"number to binary" ( [unicode], 2 ) ), #"Changed Type1" = Table.TransformColumnTypes ( #"Added Custom1", { { "binary number", type text } } ), #"Duplicated Column" = Table.DuplicateColumn ( #"Changed Type1", "binary number", "invisible sequence" ), #"Replaced 1 with zero width space" = Table.ReplaceValue ( #"Duplicated Column", "1", #"zero width space", Replacer.ReplaceText, { "invisible sequence" } ), #"Replaced 0 with zero width non-joiner" = Table.ReplaceValue ( #"Replaced 1 with zero width space", "0", #"zero width non-joiner", Replacer.ReplaceText, { "invisible sequence" } ) in #"Replaced 0 with zero width non-joiner"
Function «Number to Binary» it’s actually a much more powerful function by Marcel Beug that I found.
All together comes out like this
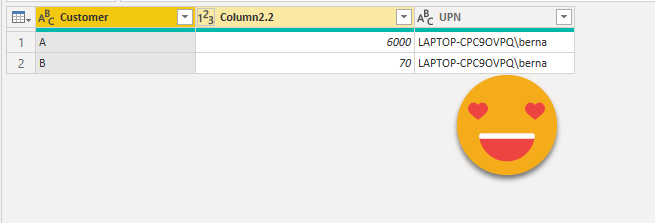
In my first approach I also created a table that would contain all User Principal Names and their equivalent string. Then the calculation group would use that table to quickly get the invisible equivalent of the user principal name.
let Source = Table.FromRecords ( { [ UPN = "LAPTOP-CPC9OVPQ\berna" ], [ UPN = "bernat@esbrinasl.onmicrosoft.com" ] }, type table [ UPN = text ] ), #"Added Custom" = Table.AddColumn ( Source, "Letters as list", each Text.ToList ( [UPN] ) ), #"Added Custom1" = Table.AddColumn ( #"Added Custom", "Invisible Sequence", each List.Accumulate ( List.Buffer ( [Letters as list] ), "", ( status, current ) => ( if status = "" then "" else status & #"zero width joiner" ) & #"letter to invisible binary sequence" ( current ) ) ), #"Added zero width joiner in the front and back" = Table.TransformColumns ( #"Added Custom1", { { "Invisible Sequence", each _ & #"zero width non-breaking space", type text } } ), #"Removed Columns" = Table.RemoveColumns ( #"Added zero width joiner in the front and back", { "Letters as list" } ) in #"Removed Columns"
which came out like this. Notice the Z’s separating each letter — (remember all these letters become zero width chars when we go to production)

With this table I was already able to set up a calculation group that would add the invisible string to the measures it was told to.
Indeed you can do it in the format string expression with a calc item that looks like this
UPN in FormatString = VAR fString = SELECTEDMEASUREFORMATSTRING () VAR upn = USERPRINCIPALNAME () VAR hiddenUpn = LOOKUPVALUE ( 'User Principal Names'[Invisible Sequence], 'User Principal Names'[UPN], upn ) VAR pFix = hiddenUpn VAR Result = pFix & fString RETURN Result
And looks fine in the visual

However all these extra charts are stripped out when you export to CSV
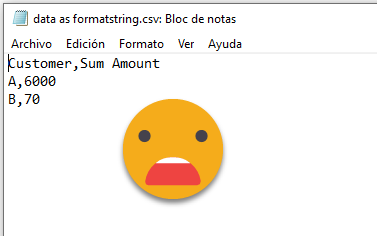
In order to get the data exported, you need to modify the value output of the calculation group, and thus you need to modify the Value expression. Something like:
UPN in Value = VAR fString = SELECTEDMEASUREFORMATSTRING () VAR upn = USERPRINCIPALNAME () VAR hiddenUpn = LOOKUPVALUE ( 'User Principal Names'[Invisible Sequence], 'User Principal Names'[UPN], upn ) VAR pFix = hiddenUpn VAR Result = pFix & FORMAT ( SELECTEDMEASURE (), fstring ) RETURN Result
The code itself is not so different, the thing is at the end, formatting the measure with the intended formatstring so it looks the same to the end user. The visual looked the same, and now the exported CSV showed all the extra characters.
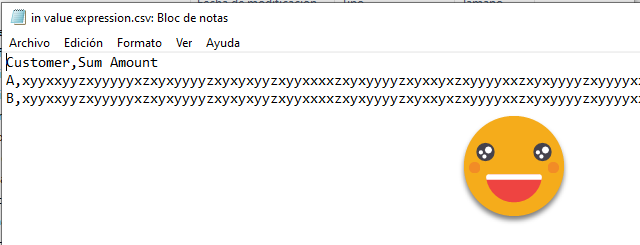
Now doing some magic in Power query, I should be able to get the regular letters back, and indeed, with a code like
let Source = Csv.Document ( File.Contents ( "H:\Mi unidad\Power BI\Username encript in measures\in value expression.csv" ), [ Delimiter = ",", Columns = 2, Encoding = 65001, QuoteStyle = QuoteStyle.None ] ), #"Promoted Headers" = Table.PromoteHeaders ( Source, [ PromoteAllScalars = true ] ), #"Split Column by Delimiter" = Table.SplitColumn ( #"Promoted Headers", "Sum Amount", Splitter.SplitTextByDelimiter ( #"zero width non-breaking space", QuoteStyle.Csv ), { "Column2.1", "Column2.2" } ), #"Changed Type1" = Table.TransformColumnTypes ( #"Split Column by Delimiter", { { "Column2.1", type text }, { "Column2.2", Int64.Type } } ), #"Added Custom" = Table.AddColumn ( #"Changed Type1", "invisible binaries", each Text.Split ( [Column2.1], #"zero width joiner" ) ), #"Added Custom1" = Table.AddColumn ( #"Added Custom", "UPN", each List.Accumulate ( [invisible binaries], "", ( status, current ) => if current = "" then status else status & #"invisible binary sequence to letter" ( current ) ) ), #"Changed Type" = Table.TransformColumnTypes ( #"Added Custom1", { { "UPN", type text } } ), #"Removed Columns" = Table.RemoveColumns ( #"Changed Type", { "Column2.1", "invisible binaries" } ) in #"Removed Columns"
The strategy is equivalent to the encoding one, convert the string into a list of letters, convert each of them and rebuild the string. Here is important that we had a character to separate each «letter» sequence so we know where to split. The function #»invisible binary sequence to letter» is a custom function that searches the sequence in the conversion table and brings back the letter. If even I could manage to create a custom function, so can you believe me. Just create a parameter with an example value of what you want to process, then do the query with all the steps that will be necessary using that paramenter. Then right click the query and say create function. It does not get easier than this.
let Source = ( myInvisibleSequence as text ) => let Source = #"Conversion Table", #"Filtered Rows" = Table.SelectRows ( Source, each ( [invisible sequence] = myInvisibleSequence ) )[Letters]{0} in #"Filtered Rows" in Source
And indeed it worked
But I didn’t really like it. One reason is that first of all you need to pre-calculate all user principal names because you have no idea who is going to be seeing that report, and also it might be that a brand new user comes and exports the data even though you have not refreshed your source data. Also you need to get it from azure active directory so potentially that could not be so easy (at my customer we tried to get data from active directory and did not work).
So I decided that UPN (user principal name) encoding had to happen inside the calculation group.
But how would that work? I need to split letter by letter, put back together… the stuff where Power query excels. But as long as it’s not recursive, you may find a way with DAX. So I gave it a try —
Encode UPN with DAX v1 = VAR fString = SELECTEDMEASUREFORMATSTRING () VAR upn = UPPER ( USERPRINCIPALNAME () ) VAR zeroWidthJoiner = "z" //UNICHAR(8204) VAR zeroWidhNonBreakingSpace = "k" //UNICHAR(65279) VAR hiddenUpn = CONCATENATEX ( GENERATE ( GENERATESERIES ( 1, LEN ( upn ), 1 ), VAR currentLetter = MID ( upn, [Value], 1 ) VAR equivalentSequence = CALCULATE ( SELECTEDVALUE ( 'Conversion Table'[invisible sequence] ), 'Conversion Table for DAX'[Letters] = currentLetter ) RETURN ROW ( "InvisibleLetter", equivalentSequence ) ), [InvisibleLetter], zeroWidthJoiner, [Value], ASC ) VAR pFix = hiddenUpn VAR Result = pFix & zeroWidhNonBreakingSpace & FORMAT ( SELECTEDMEASURE (), fstring ) RETURN Result
However, this did not work —

«z» should be separating sequences, if they are together is that the letter was not found, how’s that even possible? So I checked with a DAX query
First I checked again, just the part where it searches for the value
EVALUATE { CALCULATE ( SELECTEDVALUE ( 'Conversion Table'[invisible sequence], "T" ), 'Conversion Table for DAX'[Letters] = "L" ) }
And that would return the alternate value, the «T» how’s that even possible, I know the L is in the table, I put it there!
So I filtered and this is what happened
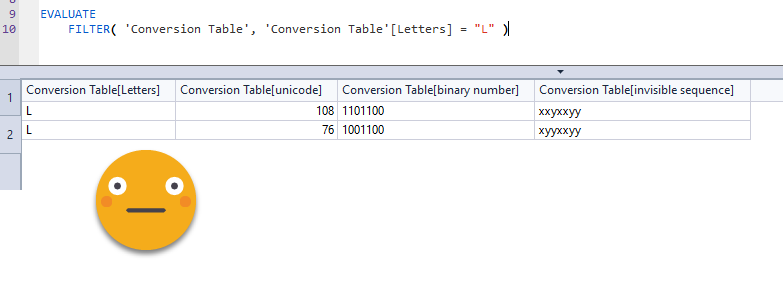
how could I forget??!
DAX is totally case insensitive!
so filtering by «L» would return both rows for upper and lower case L, and they have different invisible sequences as they are different chars in Power Query!
Well the fix was not that hard. To identify a user (the original purpose of the whole thing) does not depend on casing, so we could just to it all in upper case, and with a smaller Conversion Table.
With the new table, it worked like a charm.
Since I was on the DAX bandwagon I thought it would be a cool exercise to reencode the name back to regular letters with yes, another calculation group of higher precedence. In order to work though I had to make sure that encodings had the same length, but once that was done, I managed to do it with this calc item
Reveal UPN DAX = VAR zeroWidthJoiner = UNICHAR ( 8204 ) VAR zeroWidhNonBreakingSpace = "k" //UNICHAR(65279) VAR valueWithUPN = SELECTEDMEASURE () VAR hiddenLettersLength = FIND ( zeroWidhNonBreakingSpace, valueWithUPN, 1, -1 ) VAR visibleValue = IF ( hiddenLettersLength = -1, valueWithUPN, RIGHT ( valueWithUPN, LEN ( valuewithupn ) - hiddenLettersLength ) ) VAR hiddenLetters = LEFT ( valueWithUPN, hiddenLettersLength ) VAR prefix = IF ( hiddenLettersLength <> -1, CONCATENATEX ( GENERATE ( GENERATESERIES ( 1, hiddenLettersLength - 1, 8 ), VAR currentChunk = MID ( hiddenLetters, [Value], 7 ) VAR letter = CALCULATE ( SELECTEDVALUE ( 'Conversion Table for DAX'[Letters], "$" ), 'Conversion Table for DAX'[invisible sequence] = currentChunk ) RETURN ROW ( "Letter", letter ) ), [Letter], "", [Value], ASC ) ) RETURN prefix & visibleValue
It’s satisfactory when it works, but not really useful as you’ll probably load an exported csv up to the model. Also a small modification in the encoding side makes the decoding to break completely. Power query decoding is more powerful as it separates sequences by the delimiter regardless of the length of each sequence.

Anyway, there’s not much more left to say on the topic. Well, maybe there is. Those exporting the data, may be interested on using the data. As it stands now, the number data is converted to text, so Excel and power query recognize it as text and if you force it to integer (even after cleaning and triming) it still produces errors instead of numbers. If that is ok you can leave it as is. If you want to keep the data as numbers, you can add the effect in just a dummy measure, or any text measure you may have which does not used as key anyway so you can modify a bit without anything breaking. If you have a «last comment» measure, for instance, that would be great. Let’s try with the actual zero-width chars and on a dummy measure for final wrap-up
It looks so innocent, and so tempting to export and leak it somewhere… (the calc group filter, and the calc group itself should be hidden for extra sneaky effect)
![]()
If we import it back it still works!
![]()
However, for some reason the Reveal UPN calc group does not seem to work, and I have no idea why, but I’ve already spent too much time on this so I’ll let it go (for while at least). If anyone wants to try his or her luck, there’s a link to the file at the end.
So is this the end?
Maybe not — putting together snippets from Phil Seamark @PhilSeamark and Owen Auger @Ozeroth from this tweet I put together a DAX query that encodes any string into a binary sequence of 0-width characters and then decodes them back to regular letters! Is it useful? not really. Is it cool? you bet!
EVALUATE VAR inputText = "Bernat Agullo" VAR inputTextUC = UPPER ( inputText ) VAR visibleMode = FALSE () VAR zeroWithSpace = IF ( visibleMode, "x", UNICHAR ( 8203 ) ) VAR zeroWidhNonJoiner = IF ( visibleMode, "y", UNICHAR ( 8204 ) ) VAR zeroWidthJoiner = IF ( visibleMode, "z", UNICHAR ( 8205 ) ) VAR zeroWidhNonBreakingSpace = IF ( visibleMode, "k", UNICHAR ( 65279 ) ) VAR my1 = zeroWithSpace VAR my0 = zeroWidhNonJoiner VAR myDelim = zeroWidthJoiner VAR myFinalSep = zeroWidhNonBreakingSpace VAR bitTable = GENERATESERIES ( 0, 7 ) VAR table1 = GENERATE ( GENERATESERIES ( 1, LEN ( inputtextUC ) ), VAR letter = MID ( inputTextUC, [Value], 1 ) VAR letterCode = UNICODE ( letter ) VAR letterCodeBinary = CONCATENATEX ( bitTable, IF ( BITAND ( BITRSHIFT ( letterCode, [Value] ), 1 ), my1, my0 ), , [Value], DESC ) RETURN ROW ( "Letter", letter, "LetterCode", letterCode, "LetterCodeBinary", letterCodeBinary ) ) VAR binaryOutput = CONCATENATEX ( table1, [LetterCodeBinary], myDelim, [Value], ASC ) //& myFinalSep VAR numEncodedLetters = DIVIDE ( LEN ( binaryOutput ) + 1, 9 ) VAR table2 = GENERATE ( GENERATESERIES ( 1, numEncodedLetters ), VAR hiddenLetters = MID ( binaryOutput, ( [Value] - 1 ) * 9 + 1, 8 ) //VAR hiddenLetterBin = SUBSTITUTE( SUBSTITUTE( hiddenLetters, my1, "1" ), my0, "0" ) <-- this does not work! VAR hiddenLettersBin = CONCATENATEX ( GENERATE ( GENERATESERIES ( 1, LEN ( hiddenletters ) ), VAR hLetter = MID ( hiddenLetters, [Value], 1 ) VAR dec = IF ( hLetter = my1, 1, 0 ) RETURN ROW ( "bin", dec ) ), [bin], , [Value], ASC ) VAR hiddenLetterNum = SUMX ( bitTable, VAR c = MID ( hiddenLettersBin, LEN ( hiddenLettersBin ) - [Value], 1 ) RETURN c * POWER ( 2, [Value] ) ) VAR theLetter = UNICHAR ( hiddenLetterNum ) RETURN ROW ( "hiddenLetters", hiddenLetters, "hiddenLetterBin", hiddenLettersBin, "hiddenLetterNum", hiddenLetterNum, "theLetter", theLetter ) ) // VAR backToLetters = CONCATENATEX ( table2, [theLetter],, [Value], ASC ) // RETURN { inputText, binaryOutput, backToLetters }
You can try it for yourself in DAX.do
As I said at the beginning is not probably something you will take to production one of these days, but I hope you enjoyed the journey of «Encoding and decoding strings with zero-width characters» either with DAX or Power Query