Orchestrating Dataset Refreshes with Power Automate and Power Apps (Part 1)

Hello hello, it’s been a while since my last post because, well because… stuff, you know.
Anyway, today I want to talk about a solution I put together at one of my customers in order to orchestrate refreshes, so that dataset refresh once the precedent ETL jobs have successfully completed (never before that) and at the same time do not overwhelm the server. I’m sure that there are a thousand other ways to do it, but I have not seen many articles on «Dataset refresh orchestration with Power Automate» so I thought that could help others facing the same struggle. In this first part I’ll focus on the Power Automate side of things and I’ll leave the Power App for the second part. Let’s start:
(Update 2023-11-14: I added the Jobs table –and modified the stored procedure– as it becomes necessary in the second part. It exists in the original setup, but I thought I could simplify things a bit for the article. Well, turns out I could not)
Some context
When I joined the customer, they already had something in place, it was a python script that read metadata from a json file on what datasets to refresh after which jobs of the SQL Server. It worked, but it was exclusively managed by IT and the reporting department had no way of knowing everything that was being programmed, so there were obsolete datasets, dependencies on jobs that where no longer running and well, people did not like it.
For a while I played with the idea that outside super-important datasets, maybe that central orchestration was overkill and maybe scheduled refresh on Power BI Service was good enough for not-super-critical datasets. However, when there were performance problems on the SQL server, those «un-managed Power BI refreshes» were an all too easy target. So everything that read from SQL server needed to be orchestrated, so that the refreshes do not interfere with the ETL jobs.
The basic setup
For this approach to work, first of all we’ll need something that is quite basic. In one hand is a Jobs table that contains the last execution of all jobs of the server. And another one with a row for each execution of each job of the server, with a name and/or id, a start and end time, and a status (basicaly «ok» or «error»). I guess that most organizations running jobs on a SQL server will have something like this. If they don’t, then probably need to set this one up first.
Next we’ll need a table to list all the datasets to refresh, and another table that will list all the jobs that need to be completed before each of the datasets can be safely refreshed. Since we probably want to monitor how these «centralized» refreshes go, we might want to add a row for each refresh also in this general executions table. Well, that’s what I did anyway.
Jobs table:
- job name
- start
- end
- result
- message
Executions table:
- job name
- start
- end
- result
- message
Datasets table:
- job name (to add a rows to Executions table)
- workspace name (for humans)
- workspace id (for the API call)
- dataset name (for humans)
- dataset id (for the API call)
- priority
- refresh id (to link with the preceding jobs table)
- Remove date (to soft-delete rows)
Preceding jobs table:
- refresh id
- preceding job name
The Power Automate Flow – Datasets Pending vs Datasets Ready
With the three tables we just introduced we have the basis. Now we need to implement the mechanism to refresh the datasets, and a way to manage the whole thing. We’ll now discuss the refresh mechanism, and we’ll leave the management of the solution for the last part of this blog post.
We build a flow that is launched every morning once. We will need a premium Power Automate license because we’ll be using the SQL Server connector.
The flow basically is a loop that repeats as long as there are datasets that need to be refreshed and have not been refreshed. How can we determine that? With a view. Since we will add a row for each execution, we need to check if there are any datasets (without remove date) that have not been successfully refreshed in the last X hours, where X can be 8h for example. The easiest way is to check how many rows does this view have:
[code language=»sql»]CREATE OR ALTER VIEW [pbi].[VIEW_DATASETS_PENDING] AS
WITH
JOBS_COMPLETED AS (
SELECT *
FROM [dbo].[Executions]
WHERE [end] >= CAST(DATEADD(DAY,-1,CONVERT(DATE,GETDATE())) AS datetime) + CAST(’23:00′ AS DATETIME)
AND [status] = ‘OK’
),
DATASETS_COMPLETED AS (
SELECT d.*,
from [pbi].[Datasets] d
INNER JOIN JOBS_COMPLETED j
ON d.[job name] = j.[job name]
),
DATASETS_PENDING AS (
SELECT d.*
FROM [pbi].[Datasets] d
LEFT JOIN DATASETS_COMPLETED dc
ON d.[dataset Id] = dc.[dataset id]
WHERE dc.[dataset id] IS NULL
AND d.RemoveDate IS NULL
)
SELECT *,
‘https://app.powerbi.com/groups/’ + [workspace id] + ‘/settings/datasets/’ + [dataset id] AS "LINK"
FROM DATASETS_PENDING
GO[/code]
This view returns a list of the datasets that have not yet been refreshed. To do so it first identifies all the completed jobs and joins them with the dataset table, since once refreshed they will be in the Executions table too. All the datasets that are not in the Execution table with a correct execution since yesterday at 11 PM (and have not been soft-deleted), should refresh; are «Pending Datasets».
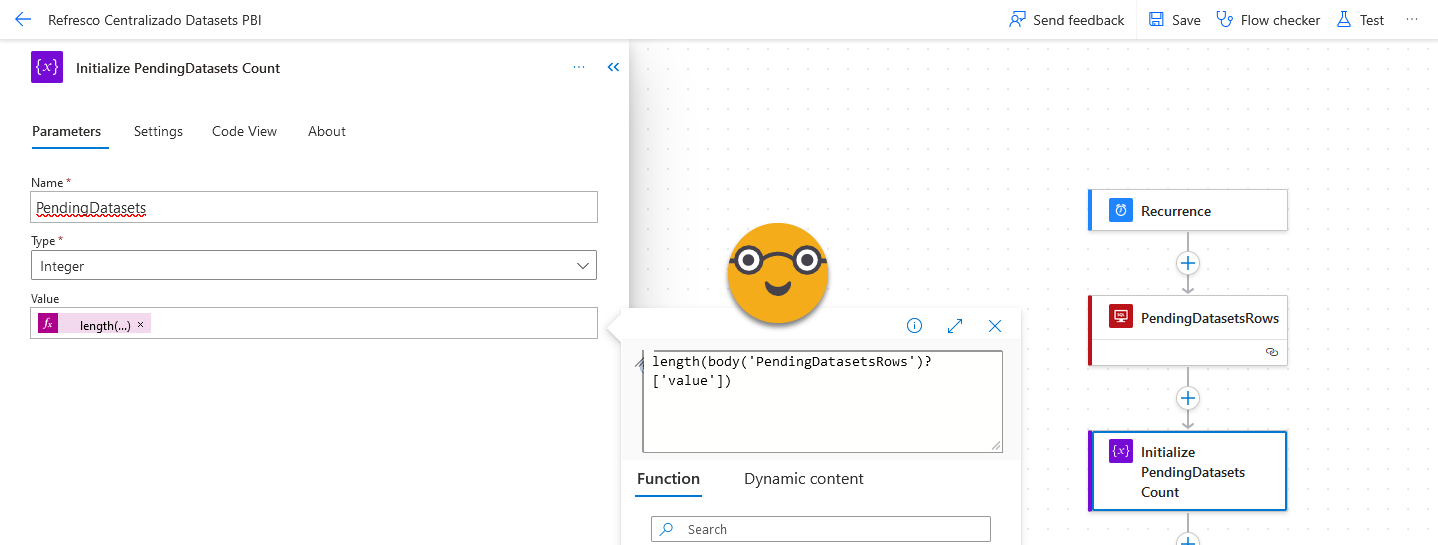
As you can see in the image, the tricky part here is how to tell Power Automate to store the number of rows of a query into a variable.
length(body('PendingDatasetsRows')?['value'])
It’s a terrible language. Get used to it. At least with the new UI you can now expand the tiny little box where you had to write it before.
Ok great, we have datasets to refresh, but this does not mean that we can launch the refreshes right away. We need to check that the preceeding jobs have successfuly completed. Well, we do that with another view.
[code language=»sql»]CREATE OR ALTER VIEW [pbi].[VIEW_DATASETS_READY] AS
WITH
JOBS_COMPLETED AS (
SELECT *
FROM [dbo].[Executions]
WHERE [end] >= CAST(DATEADD(DAY,-1,CONVERT(DATE,GETDATE())) AS datetime) + CAST(’23:00′ AS DATETIME)
AND [status] = ‘OK’
),
DATASETS_COMPLETED AS (
SELECT d.*
from [pbi].[Datasets] d
INNER JOIN JOBS_COMPLETED j
ON d.[job name] = j.[job name]
and d.[remove date] is null
),
DATASETS_PENDING AS (
SELECT d.*
FROM [pbi].[Datasets] d
LEFT JOIN DATASETS_COMPLETED dc
ON d.[dataset id] = dc.[dataset id]
WHERE dc.[dataset id] IS NULL
AND d.[dataset id] IS NOT NULL
AND d.[remove date] IS NULL
),
DATASETS_NOT_READY AS (
SELECT d.*
FROM DATASETS_PENDING d
LEFT JOIN pbi.[Preceding Jobs] p
on d.[refresh id] = p.[refresh id]
LEFT JOIN JOBS_COMPLETED j
on p.[preceding job name] = j.[job name]
WHERE j.[job name] IS NULL
),
DATASETS_READY AS (
SELECT d.*
FROM DATASETS_PENDING d
LEFT JOIN DATASETS_NOT_READY n
ON d.[dataset Id] = n.[Dataset Id]
WHERE n.[Dataset Id] IS NULL
),
SELECT *
FROM DATASETS_READY
[/code]
However if we stop here, once a key process completes, it may create an avalanche of refreshes that overwhelms the server if many datasets have it listed as a preceding job. Such a process can be the last one of the DWH or a key ODS database (I know we should not use ODS databases as Power BI data sources, but life is complicated, alright?).
So we’ll make the view longer, creating a DATASETS_READY_2 that will limit how many datasets shall be refreshed with a certain preceding jobs. Something I learned in the process is that we need also to prioritize those that have no attempt in the last hours, meaning that if we try to refresh a dataset and it fails it will then first try to refresh the other ones before trying to refresh it again. We do all that with some good old SQL.
[code language=»sql»]
DATASETS_DWH AS (
SELECT [refresh id]
FROM [pbi].[Preceding Jobs]
WHERE [preceding job name] = ‘[DWH] Final’
AND [refresh id] IS NOT NULL
),
DATASETS_FINANCE AS (
SELECT [refresh id]
FROM [pbi].[Preceding Jobs]
WHERE [preceding job name] = ‘[ODS] FINANCE’
AND [refresh id] IS NOT NULL
),
DATASETS_TRIED AS (
SELECT *
FROM [dbo].[Executions]
WHERE [end] >= CAST(DATEADD(DAY,-1,CONVERT(DATE,GETDATE())) AS datetime) + CAST(’23:00′ AS DATETIME)
AND [status] <> ‘OK’
),
DATASETS_READY_2 AS(
–max of 4 datasets reading from the dwh
SELECT *
FROM (
SELECT R.*,
ROW_NUMBER() OVER(
PARTITION BY 1
ORDER BY
IIF(T.[job name] IS NULL, 0, 1) ASC,
R.[priority] ASC) N
FROM DATASETS_READY R
INNER JOIN DATASETS_DWH E
ON R.[refresh id] = E.[refresh id]
LEFT JOIN DATASETS_TRIED T
ON R.[job name] = T.[job name]
) V
WHERE V.N <= 4
UNION ALL
–max of 2 datasets (that do not read from dwh) and read from finance ods database
SELECT *
FROM(
SELECT R.*,
ROW_NUMBER() OVER(
PARTITION BY 1
ORDER BY
IIF(T.[job name] IS NULL, 0, 1) ASC,
R.[priority] ASC) N
FROM DATASETS_READY R
INNER JOIN DATASETS_FINANCE S
ON S.[refresh id] = R.[refresh id]
LEFT JOIN DATASETS_DWH E
ON R.[refresh id] = E.[refresh id]
LEFT JOIN DATASETS_TRIED T
ON R.[job name] = T.[job name]
WHERE E.[refresh id] IS NULL –remove those that also ready from dwh
) V
WHERE V.N <= 2
UNION ALL
SELECT R.*, 1 N
FROM DATASETS_READY R
LEFT JOIN DATASETS_DWH E
ON R.[refresh id] = E.[refresh id]
LEFT JOIN DATASETS_FINANCE S
ON S.[refresh id] = R.[refresh id]
WHERE E.RefreshId IS NULL
AND S.RefreshId IS NULL
)
SELECT *,’https://app.powerbi.com/groups/’ + [Workspace ID] + ‘/settings/datasets/’ + [Dataset ID] AS "LINK"
FROM DATASETS_READY_2
GO[/code]
Here the key are the subqueries DATASETS_DWH and DATASETS_FINANCE, containing all the datasets that have certain jobs as their predecessors. Of course some datasets may be in both subqueries, but this is taken care of by filtering from the list of dataset that read from finance. If you are not acquainted with the function ROW_NUMBER() I recommend you check it out as it solves numerous use cases. Here we specify «partition by 1» meaning we are not really partitioning our rows, we want a general row number. The order by is the key: «IIF(T.[job name] IS NULL, 0, 1)» this means that it will sort first those datasets that are not in the DATASETS_TRIED subquery. And between those, it will sort ascending by priority number.
As you can see you can add as much logic as you want to come up with a list of the datasets that are to be refreshed right away. This is manual, you need to look how the refreshes go, and modify the number of simultaneous refreshes accordingly and if necessary add yet another «sensitive» database where only a maximum number of datasets can be simultaneously refreshing. In general most datasets should read only from the DWH, but life is complicated. Do what you have to — I will not judge you!
Oh I almost forgot, as you see the final query builds the link to the dataset so that you can check what is going on if late into the morning or in the afternoon there are still «ready» to refresh datasets. Most likely there were some errors so you might want to look into those.
So let’s now step back a bit and see where these two views come into play in the general flow
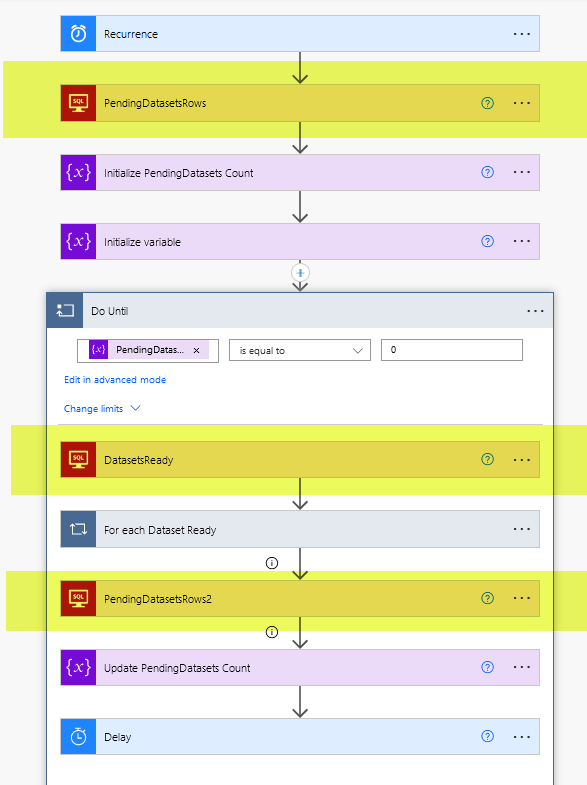
Reading the latest refresh of each dataset
Basically we keep looping while there is work to do and for each loop we do what we can with the Datasets Ready. As you can imagine, under «For each Dataset Ready» there’s quite a bit more logic. At first though it does not look too bad.
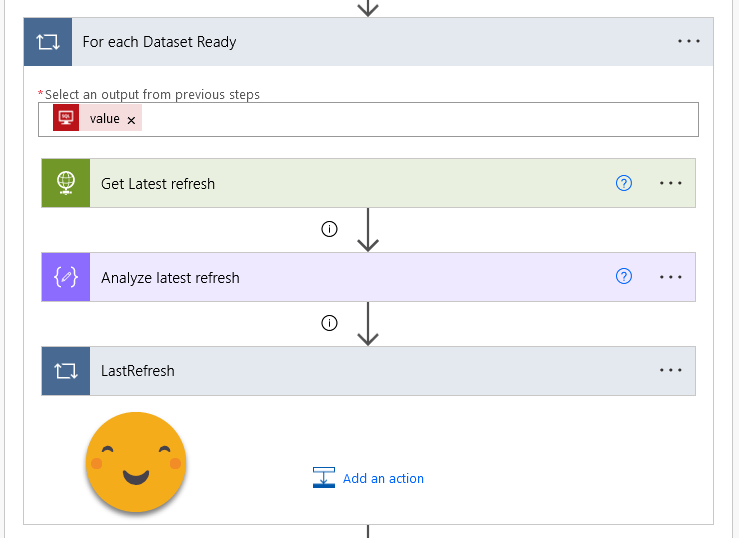
Here setting up the first box is the trickiest one. Basically what we’ll to is use Power BI Rest API to get the latest refresh of the dataset (remember we are iterating all the ‘ready’ datasets) and then we’ll see how did that refresh go, when it did start when did it end and so on. In order to be able to do this call you will need some good friends in the IT department. You will need an «App Registration». I know the name makes no sense. But is even worse that is normally referred to as «Service Principal» which does not make much sense either. Is a way to give permission to do things to something that is not a user, so to say. Which is good for automating stuff. This app registration will need a secret (which basically works like a password — you can only see the contents when you create it, never again unless you copy it somewhere safe) and then you need to give API permissions to that ‘App Registration’. In particular for this call we need permissions of Power BI service, the Dataset.Read.All permission (which is a «Delegated» permission. Don’t ask).
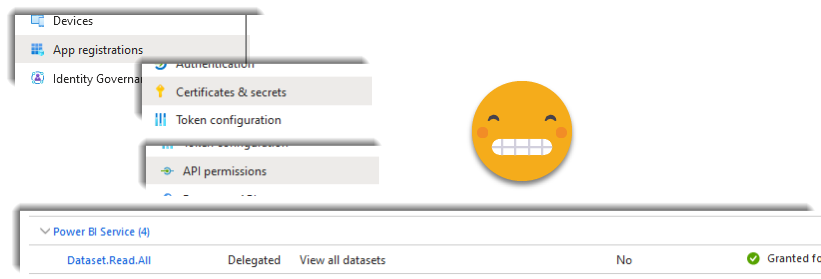
You would think that this is enough but not. Now you need to go into the tenant settings of Power BI service and allow service principals to use the read-only admin API. And just add the regular API and enhanced responses just in case.

In these three sections I added limited the permission to a security group containing the App Registration. Yes, you will need to ask your IT friend to do that too. Hey the good news is that this being Power Automate you don’t need to request tokens and stuff like that. It is all taken care of by the HTTP connector. Speaking of which, there are quite a few things to set up:
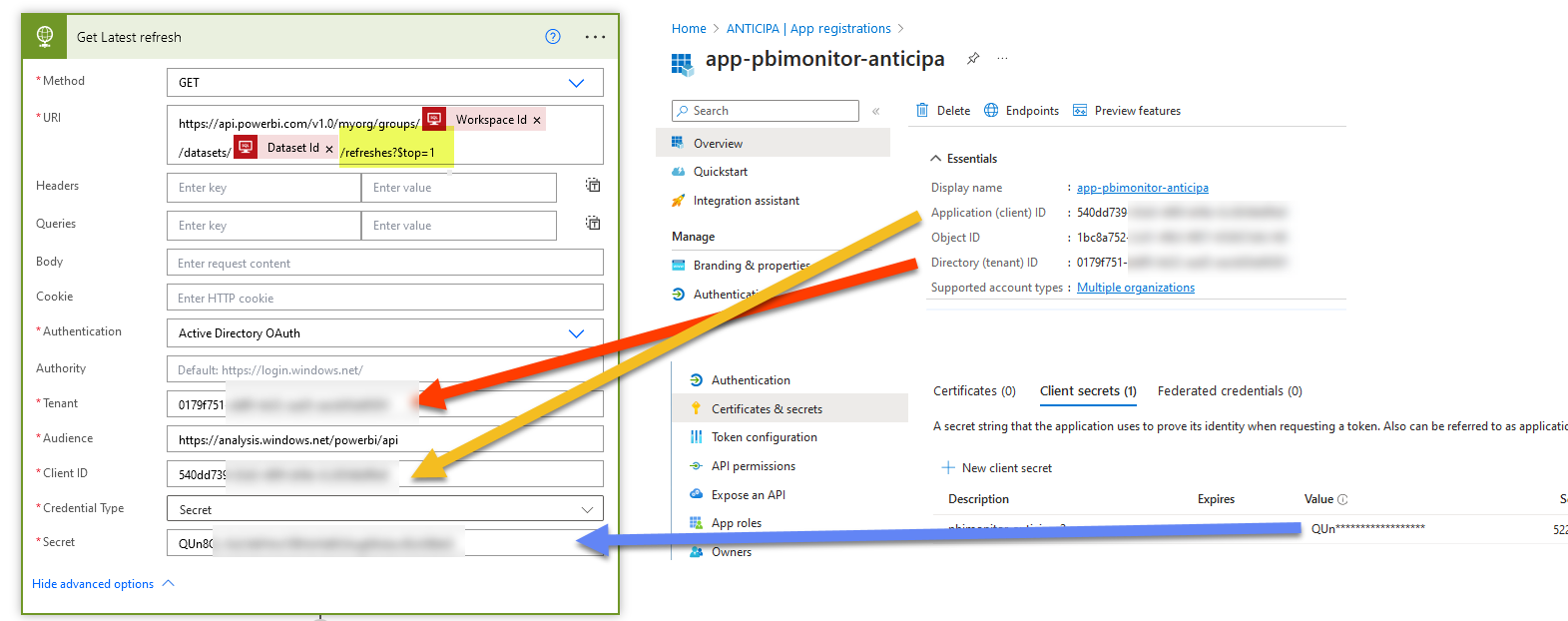
See that we use the same URI as the documentation, but replacing workspace id and dataset id by the values of the row that we are currently iterating. Also notice that we are just getting the latest refresh so we’ll add a ?$top=1 at the end of the call so we just get a single refresh in the response.
Oh and one more thing! for this call to actually work, you need to have the service principal in the workspace as a member! This in theory can be done with APIs too, but after lots of sweat an tears I’ve given up with it for a while. My attempts have been with Azure Data Factory, and I know that Vahid has some awesome post on the topic doing it with Power Automate, so I might give it a try see if I have better luck. I just add it to the workspace and I’m good to go. After all you only need it in workspaces where you want to orchestrate the refresh of a dataset, so you know which workspaces you need to look into.
Reading the JSON
The API returns a JSON with the details of the latest refresh, and to be able to use the attributes we need to map that with a «Parse JSON» operation. It’s very convenient that you can just paste a sample output, and it will generate the schema definition for you. On the following steps you can use the value of the different properties. Very smooth.
The result of the parsing is an array, so even though we only have one refresh we need to do it with a «For each» control. Whatever.
Refreshing, retrying and registering to the database
And here is where things get a bit out of control.
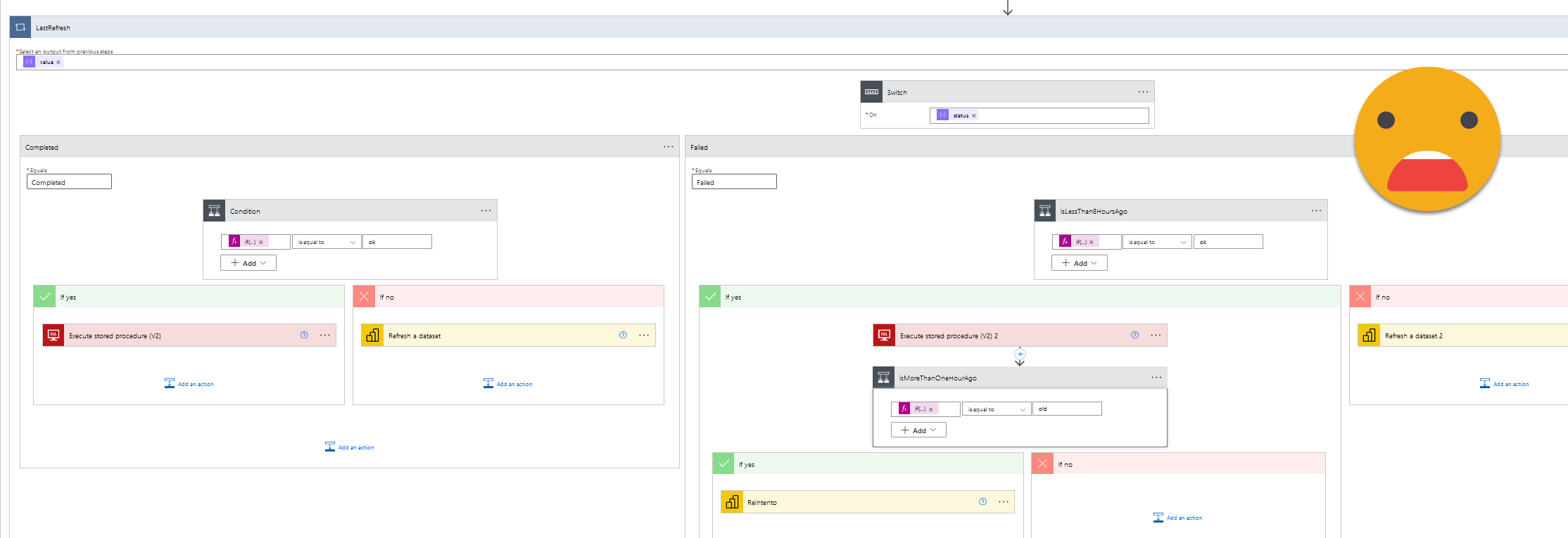
Well, don’t get too overwhelmed by the figure. Power Automate makes simple programming blocks look huge.
First of all, we have a switch statement based on the result of the latest refresh of the dataset coming from Power BI Service. This can be «Completed», «Failed» and some other values, but we don’t care about those. Now if the result is completed, we need to check when did that happen. Particularly we want to know if it’s a refresh that happened during the previous 8h or not. So we do that with a condition block. The expression, as usual, is the tricky part. In this case it looks like this:
if(less(addHours(utcNow(), -8), items('LastRefresh')?['startTime']), 'ok', 'old')
The expression returns «ok» if the current time minus 8 hours is less than the start time of the last refresh. Which is the same to say that the last refresh happened in the last 8h. If that is true, then we need to make sure that this refresh is registered in the database. Otherwise (e.g. the latest refresh is from more than 8h ago) then it’s time that we finally refresh the dataset.
But wait a minute — how to we write to the database?
It took me a while to figure out that you can’t really write arbitrary SQL from power automate and expect it to run it for you. So even though is a bit of a pain we need to do it though stored procedures. I created a stored procedure to register refreshes that complete and refreshes that fail.
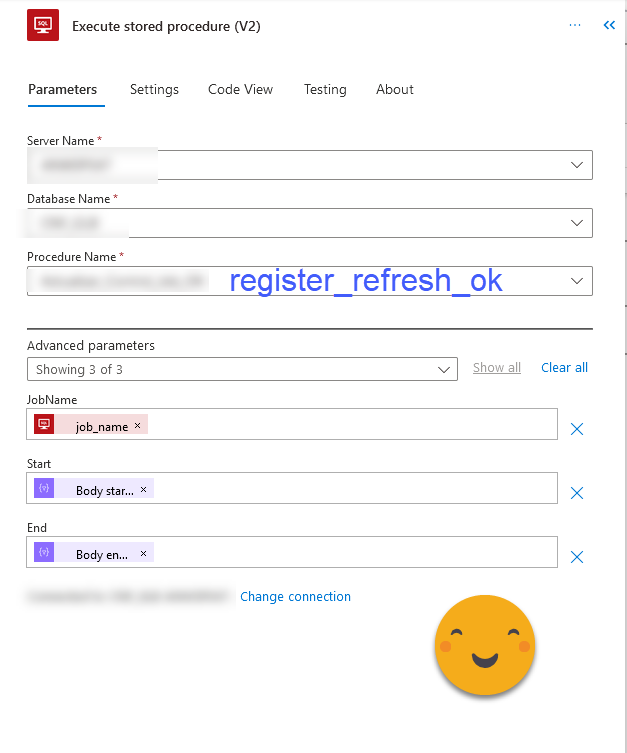
The code for the stored procedure is not too complex, but there’s a couple things to watch out for
[code language=»sql»]ALTER PROCEDURE [dbo].[Register_Refresh_OK]
@JobName NVARCHAR(250),
@Start DATETIME,
@End DATETIME
AS
BEGIN
SET NOCOUNT ON;
/*if it’s the first time add to the jobs table*/
IF(
SELECT COUNT(*)
FROM [dbo].[Jobs] H
WHERE H.[job name] = @JobName
) = 0
BEGIN
INSERT INTO [dbo].[Jobs]
(JOB_NAME)
SELECT
job_name as "JOB_NAME"
/*Extra fields such as job description, type etc*/
FROM pbi.[Datasets] r
WHERE job_name = @JobName
END
/*transforn timestamps to local time if needed*/
DECLARE @StartLocal DATETIME = DATEADD(mi, DATEDIFF(mi, GETUTCDATE(), GETDATE()),@Start)
DECLARE @EndLocal DATETIME = DATEADD(mi, DATEDIFF(mi, GETUTCDATE(), GETDATE()),@End)
/*if it’s not yet in the Executions table*/
IF (
SELECT COUNT(*)
FROM [dbo].[Executions] E
WHERE E.[job name] = @JobName
AND H.[start] = @StartLocal
) = 0
BEGIN
/*update jobs with the last execution info*/
UPDATE [dbo].[Jobs] with (rowlock)
SET
[status] = ‘OK’,
[start] = @StartLocal,
[end] = @EndLocal,
[message] = ‘The process has finished correctly’
WHERE
[job name] = @JobName
/*insert in Executions table*/
INSERT INTO [dbo].[Executions]
([job name],[status],[start],[end],[message])
SELECT job name],[status],[start],[end],[message]
FROM [dbo].[jobs] J
WHERE [job name] = @JobName
END
END
GO[/code]
It took me a while to realize that the times I was adding to the tables where 2h earlier than when they really happened. Until I realized I was writing UTC times and the Executions time was in local time… If that’s your case, then you can get the code to translate to local time (which of course I found googling my troubles). Otherwise just go ahead with UTC times as they come from the JSON file. The second thing is to be careful not to duplicate rows. We might have already added the row. Even if it should not be possible, just be careful and check if the row is already there before adding it. The primary key is job name + start time. This is what the code does.
When the latest refresh has been in the last 8h (same expression as before) we also need to make sure this has been registered in the database with a very similar stored procedure (you can probably do it with a single procedure and some extra parameter). Then of course we might want try it again. But not like immediately as this may overwhelm the server without much success since the conditions might be the same ones that made it fail de first time. So if you want to launch a retry after 4h you can do a switch statement with this expression
if(less(addHours(utcNow(), -4), items('LastRefresh')?['startTime']), 'ok', 'old')
if this expression returns «old» it means that last failed refresh is more than 4h ago so it’s safe to try it again. It’s also a good way not to hit the 8 daily scheduled refreshes you have with a Pro license.
Final touches
And that’s pretty much it, as I mentioned it earlier, once we have iterated through all the datasets, we need to update the count of pending datasets and stay on the loop or exit if there are no pending datasets anymore. It’s wise to put some delay because at some points there might be pending datasets but not ready datasets (maybe there’s an ETL job failed and they had to re-run it), and there’s little point on running the same queries every second. So wait a a few minutes and try again, that’s what the delay is for.
End of Part 1
Yes, I first thought of putting the Power Automate and Power App in the same article but this is already too long. So I’ll stop here for now. Maybe at some point I’ll create some template, but I don’t think it’s worth it. I think it’s best to build it yourself with a guide like this one and build it in a way that makes sense to you. If your way is better than mine, let me know! I’m new to Power Automate and I might be missing on many tricks that make things easier or better in general.
Thank you for reading and watch out for Part 2!
Regards,