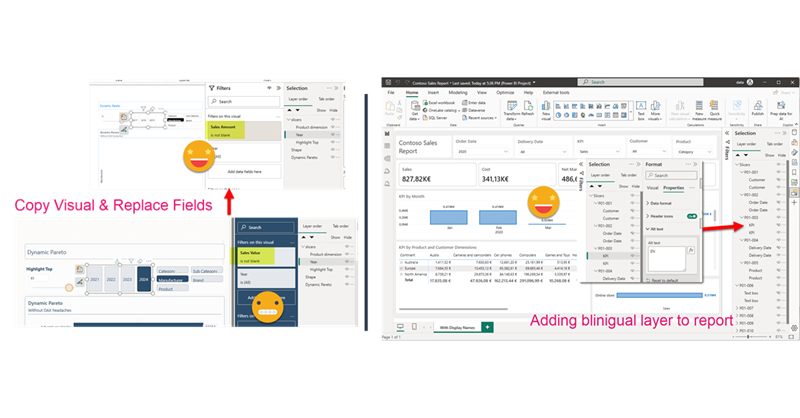
Hello again. Today I’ll introduce two new Tabular Editor C# Scripts that might help you at some point if you are already using the PBIR format (which is in preview, so don’t rush it!). The first one is to copy a visual, which at first does not look impressive, but remember that swapping fields in Power BI desktop breaks many more things that you would expect. Next we’ll see a script I built for myself if I ever have to make another report bilingual. The initial report preparation phase is now automated. That’s only part of the work, but still it’s an nice improvement.
Continue Reading..